
这是论文分享的一部分内容,因为资料需要分享所以整理了一下发了上来。主要是顺着14-18年的四篇“爆款论文”梳理了一下attention思想的发展方向,对论文的讲解并不是很多,其中可以展开的地方也很多,只是浅尝辄止了一下。
Slides可以在这里下载
今天主要介绍几篇关于Attention的论文,一起按照时间梳理一下近期的一些Attention机制相关的研究,刨去论文里面包装的部分,探寻Attention从一种直觉到最终成熟的过程也是十分有趣的。
其实Attention并不是指代某一种网络,而是一种思维。所以严格来说他应该被称作Attention Based Network 或者 Attention Mechanism。
比如我们现在最经常说的Attention事实上是Self-attention中的一个变种,真正的出现是在2017年,后面我们会介绍到。但是事实上attention很早就在各个方向上有不同的应用。
0.Recurrent Models of Visual Attention 2014
论文地址
https://papers.nips.cc/paper/5542-recurrent-models-of-visual-attention.pdf
我们首先从一篇增强学习实现attention的论文开始,这篇文章的作者团队包括Alex Graves, Volodymyr Mnih 都是强化学习的大佬,强化学习简单的说就是有一个agent,他需要做出一系列的决策,而这一系列决策最终导致了一个结果。通过这个结果再对他的决策进行修正。而这篇文章中通过构建Glimpse,使得这个agent能感知到的就是Glimpse里面的内容,且在每一个时间点,agent 只能根据有带宽限制的感知器来观察全局,同时要求这个agent在看到东西之后决定下一次Glimpse在什么地方(l_s),自主的控制如何布置感知器的资源,以及决定是否还需要继续观察。
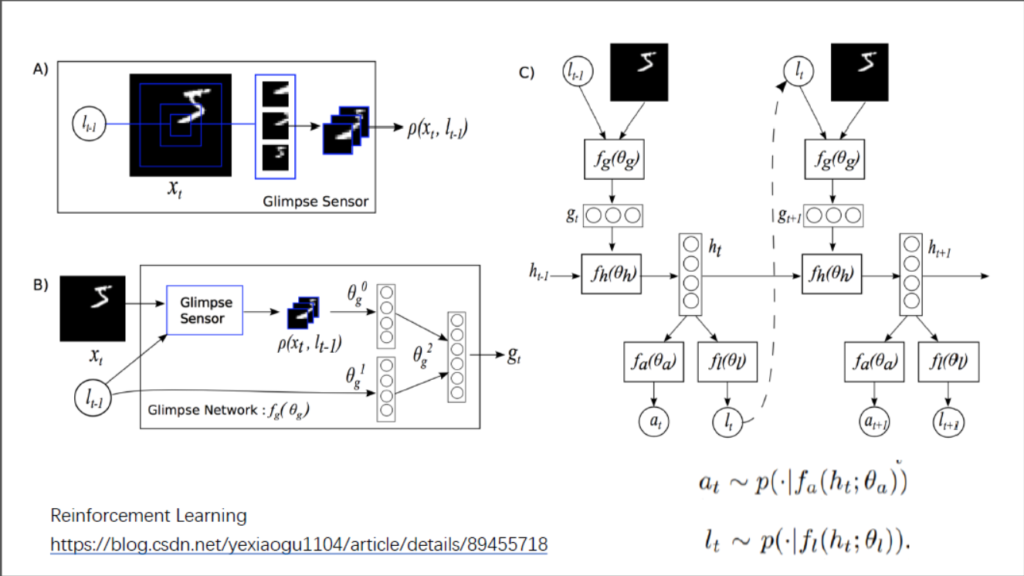
由于该环境只是部分可观察,所以他需要额外的信息来辅助其进行决定如何行动和如何最有效的布置感知器。每一步,agent 都会收到奖励或者惩罚,agent 的目标就是将奖励最大化。
由于Reinforcement Learning作为机器学习算法(可以认为)最复杂的一部分,如果有对优化过程感兴趣的可以仔细关注一下这个博客。
1.Attention is all you need 2017
论文地址
https://arxiv.org/abs/1706.03762
Blogs
https://spaces.ac.cn/archives/4765
这篇文章是Attention机制最原始的一篇文章,也是提出了Transformer的一篇文章。为了点题,证明只用Attention不用卷积也不用RNN可以在机器翻译领域做到State-of-the-art,有些地方的确有些牵强附会,但是并不妨碍他是一个很有启发意义的实现,后来的SA-GAN,Non-local Network其实都是他的变型。
近些年很切实可感的是:在序列模型中(NLP,ASR),大家渐渐的不再用TDNN或者RNN进行序列的学习,在NLP的领域出现了Attention模型,而在ASR的领域,很明显的能感觉到,大量的实验开始从频谱、相位谱直接利用CNN对音频进行建模。
主要有两个原因:
一个是RNN对长距离的关系(Non-Local)的发现与优化愈发困难,在LSTM后就没有比较好的改进,而LSTM本身训练难度也较大;同时外部记忆模块可积分神经计算机,神经图灵机等一系列结构距离实用还有较远距离,一直无法解决长距离关系发现的问题。(其实CNN也是如此,稍长一点的距离就需要小核多次卷积或者较大的卷积核)
另一方面在于RNN的不可并行性,且参数规模相对庞大,无法有效的利用运算能力。比如在训练语音相关的模型,LSTM的时候,很难把GPU利用率推到90%,但CNN相对就简单得多。
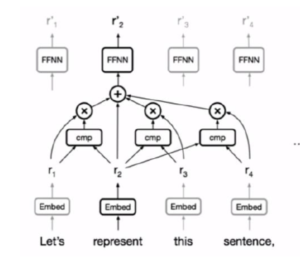
单一Attention Head 的结构示意图
如图所示,在Attention机制里面,对任意一个位置(图中当前represent词处),都分别跟句子中的每一个单词做对比(cmp),得到其余单词与当前位置的相关性,将相关性作为权重,对每个词向量加权相乘,送入接下来的网络。
这样的话有几个好处:
1.对于任意两个位置之间的“路径长度”是一个定值
2.在一次传播的时候很好并行计算
3.有足够的“Multiplicative Interaction”
在这篇论文中,他们完全放弃RNN,使用KV-Pair和Query的方式,由一个attention在原有的序列的基础上构建KV-Pair,由另一个attention在现有已生成的序列上构建Query,根据Query以及原有序列的Pair去生成最后的结果。
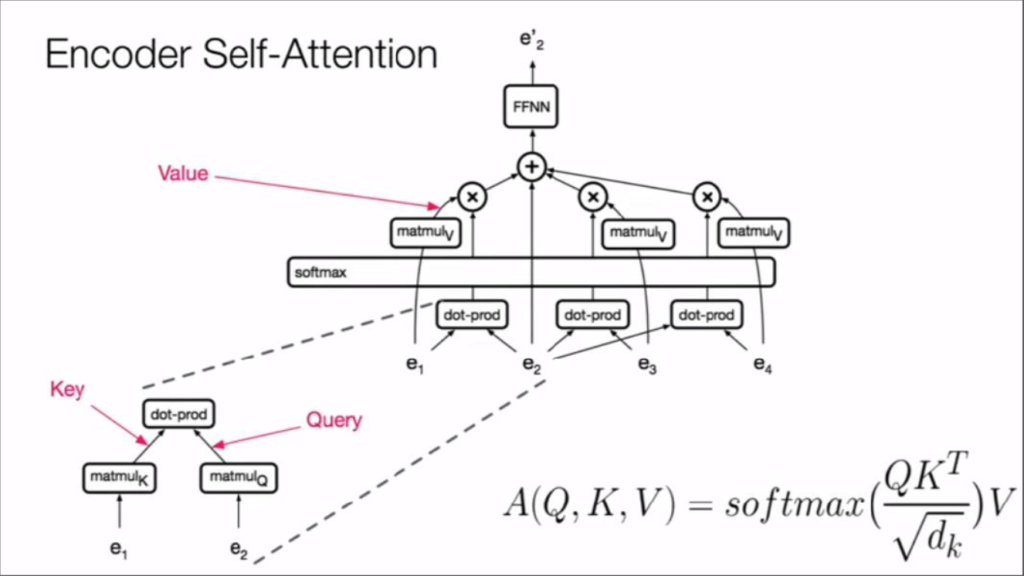
其中Q与K的转置相乘,可以认为是在Query与Key的空间中,对Query与每个Key求cosine距离,相近的会产生更大的值,而在归一化之后,得到了上文cmp的效果,将权值做softmax回归之后,再分别与Key对应的Value相乘。就得到了被“attention”加权过的语意向量,再送入下面的前馈网络中。
在真正实现的时候,为了表明每一个语意向量(embedding)的位置,他构建了一个位置函数(p)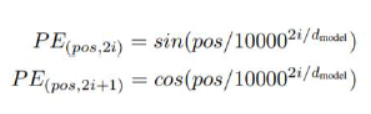
就像[sin(x),sin(2x),sin(4x)]一样,对向量进行类似二进制的编码。这个方式以及位置编码事实上在NTM,DNC上面都有过实现,但这边比较神奇的事情就在于他work了,效果很好。
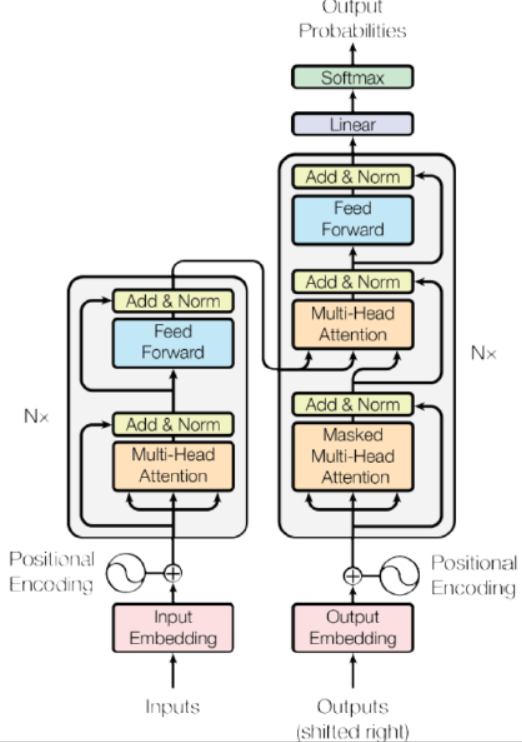
在加入PositionalEncoding之后,整个模型分别采用了3套Multi-Head的Attention机制,一套负责编码输入信息,一套负责编码当前已经翻译的信息,而一套负责根据当前输入的信息,编码输入部分的输出。
这篇文章标志着我们现在所尝试的自注意力网络的成型,在翻译模型里面仅依靠注意力机制(不依靠CNN/RNN)就实现了State of the art的结果。
顺便安利一下斯坦福CS224的Lecture14,其中邀请了这篇论文的作者来对这部分进行了介绍,讲的比较的原汁原味,很多KeyPoint(包括Multi-head的意义)都覆盖到了。
2.Image Transformer ICML 2018
论文连接:https://arxiv.org/pdf/1802.05751.pdf
将上面的Transformer架构应用在像素上,我们就获得了Image Transformer。与前文不同的地方在于对于像素,我们要有不同的光栅化(离散化)的方法,使得在生成像素的时候可以有不同的语意信息,与合适的Memory矩阵。
论文单个单个像素的对图片进行生成,包括超采样和条件生成(conditional generation)两个任务,效果超过PixelCNN和PixelRNN。然而模型效果与GAN比起来要差很多,但是在结构化的内容上能取得很不错的效果,并且其实Transformer的架构比GAN要晚很多,应该会有一些提升空间。
3.Non-local Neural Networks CVPR 2018
https://walkccc.github.io/blog/2018/10/27/Papers/nonlocal-nn/
这篇文章是Kaiming He指导的作品,发现了Transformer是Non-Local Means的一个特例,然后主要把之前网络里面Non-Local Means和Transformer的架构结合了一下,构建了一个“Non-local Block”实现的很快,效果也很好。
文章主要对比了再卷积过程中不同层级的Feature-Map中加入不同规模的Attention机制对神经网络的影响。没有太多源发的创新点,把传统的视觉领域的方法进行了迁移,不过也是一篇比较扎实的文章。
4.Self-Attention GAN
论文连接:SelfAttention-GAN
Ian Goodfellow团队
“Finally, Dogs with four legs! ”
由于Attention能比较好的探寻long-range dependency,在前面Image Transformer的文章里也发现了其可以很好的构建结构信息,而GAN在生成结构信息方面还是相对弱一些的,所以文章尝试在GAN的生成器与判别器中都加入了non-local的模块,希望判别器可以从更长远的角度判别生成质量,而不仅仅是对纹理等小规模特征进行判别,同时要求生成器可以在较大尺度上生成合理的结构化信息。
同时本文加入了TTUR和谱归一化(Miyato et.al),证明了这两种方式确实能稳定GAN的训练。
最终在生成具有较强结构化信息的分类时,性能相比先前最优有较大的提高;在生成无较强结构化信息的类时,性能有轻微的减弱;总体性能有不小的提高。
+1.Multi-Channel Attention Selection GAN with Cascaded Semantic Guidance for Cross-View Image Translation(Oral)
论文链接:https://arxiv.org/abs/1904.06807
源码链接:https://github.com/Ha0Tang/SelectionGAN
这篇文章做的内容是视角转换,而且是卫星图转换为街景图的任务。只是Attention思想的一个应用了,结果好的有点难以置信。有一点小小的疑问,不知道具体数据集的分割方式,而且论文里面展示的内容也都是相似场景的。有没有可能是网络只是把Aireal的数据按照固定方式折叠起来,重新生成回去的时候事实上只是把隐藏的数据重新展开了(?)。